 Adam Nyberg
Adam Nyberg
Real-Time Sync Engines
Real-time sync engines are the next engineering productivity boost 🚀. This post will give you a high-level understanding of how they work and how they make developers more productive.
What are sync engines?
Sync engines are systems that synchronize data across different devices, applications, or services. They ensure that changes made in one location are reflected in others, maintaining consistency and up-to-date information.
They have been popularized in highly interactive apps like Figma, Linear, Notion, etc. Linear is famous for its sync engine, which is described in this talk.
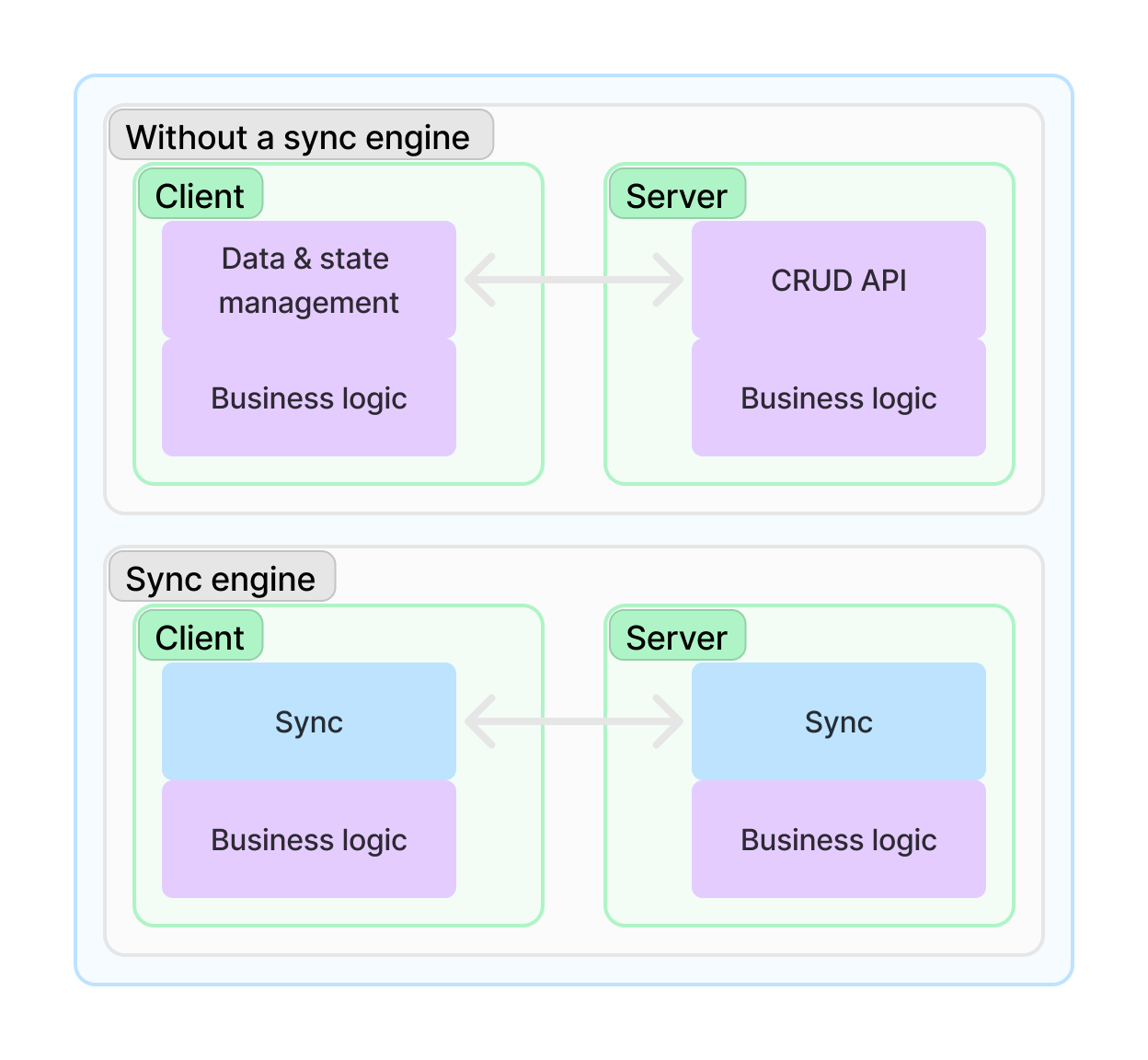
Most people emphasize sync engines' end-user benefits such as performance with instant UI updates and offline support. But, even more importantly, the developer benefits are massive and engineers can dedicate significantly more time to product development!
- No more building basic CRUD APIs. How many times have you built caching? Implement rate limiting? Error handling? API schema? Request validation? Logging? Type safety across client and server? Testing?
- No more building client caching, refetching, pagination, retrying updates, offline support, etc.
- Reduced server requirements.
- Write operations can tolerate longer response times since all writes optimistically update the UI and can be queued, helping manage load spikes effectively.
- The most relevant data resides on the client, so after the initial sync, there is less data to load with each page request. The initial sync can even be partial to speed up the first load.
Some sync engines take a more “full-stack” approach, providing tooling for authentication and authorization, file uploads, a managed database, monitoring, and observability, while other projects focus primarily on data syncing.
Abstract away complexity
With some kind of sync engine, you, as the developer, should be able to ignore everything related to moving data between servers and clients. You should only have to care about and build out your business logic, some of which should run on the client and some on the server.
Imperative to declarative across the stack
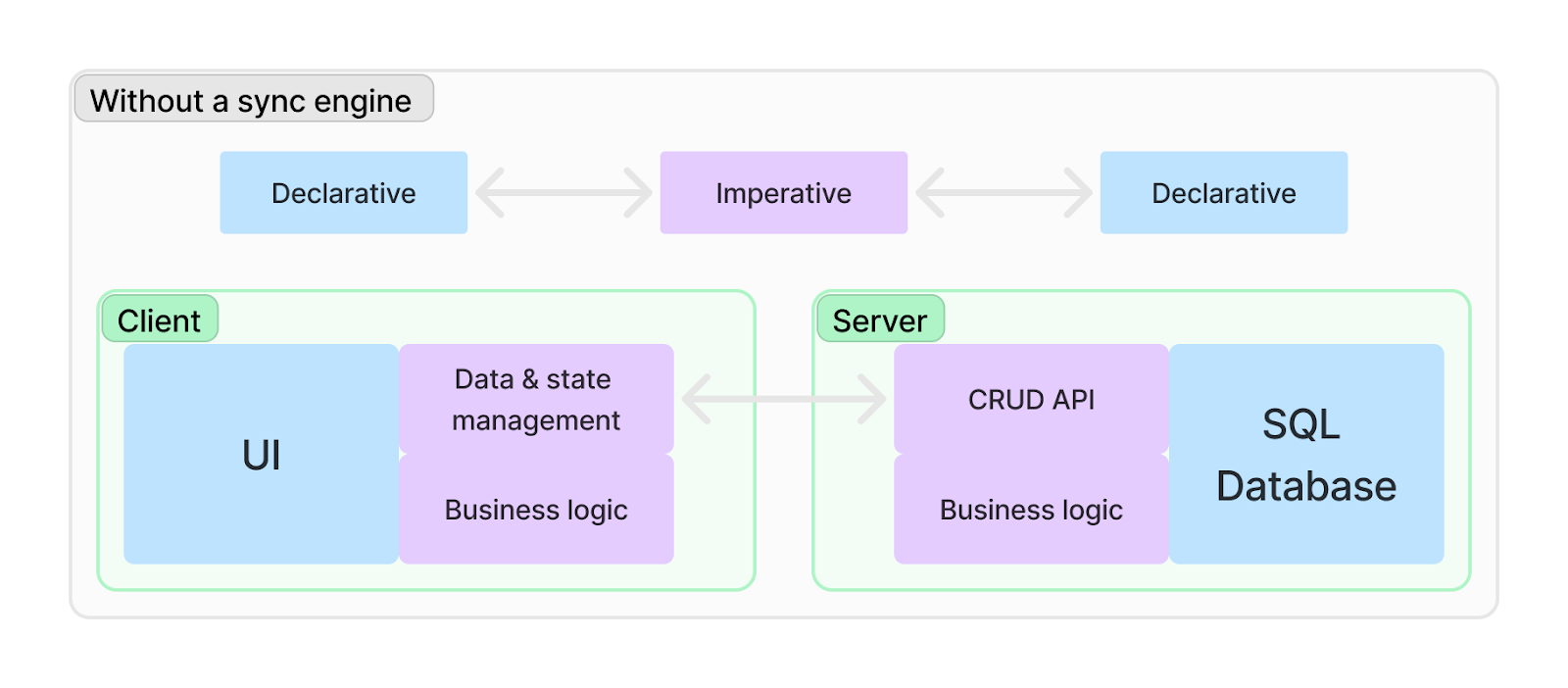
Another interesting perspective is that web development experienced a major change when tools like React arrived. We could now just provide a state and declare what we wanted to be rendered, React would figure out all the details around rerendering, etc. The code became more declarative.
Data access and updates have long been declarative using SQL. Nowadays, most apps are declarative UIs and declarative data stores glued together with an imperative CRUD API as seen below.
Sync engines finally allow us to glue together UIs and data stores declaratively, resulting in a lot less logic for web engineers. Sync engines don’t solve all your problems, but they solve a lot. Web engineers can now move up one abstraction level and increase productivity! With a sync engine, it might look something like this instead.
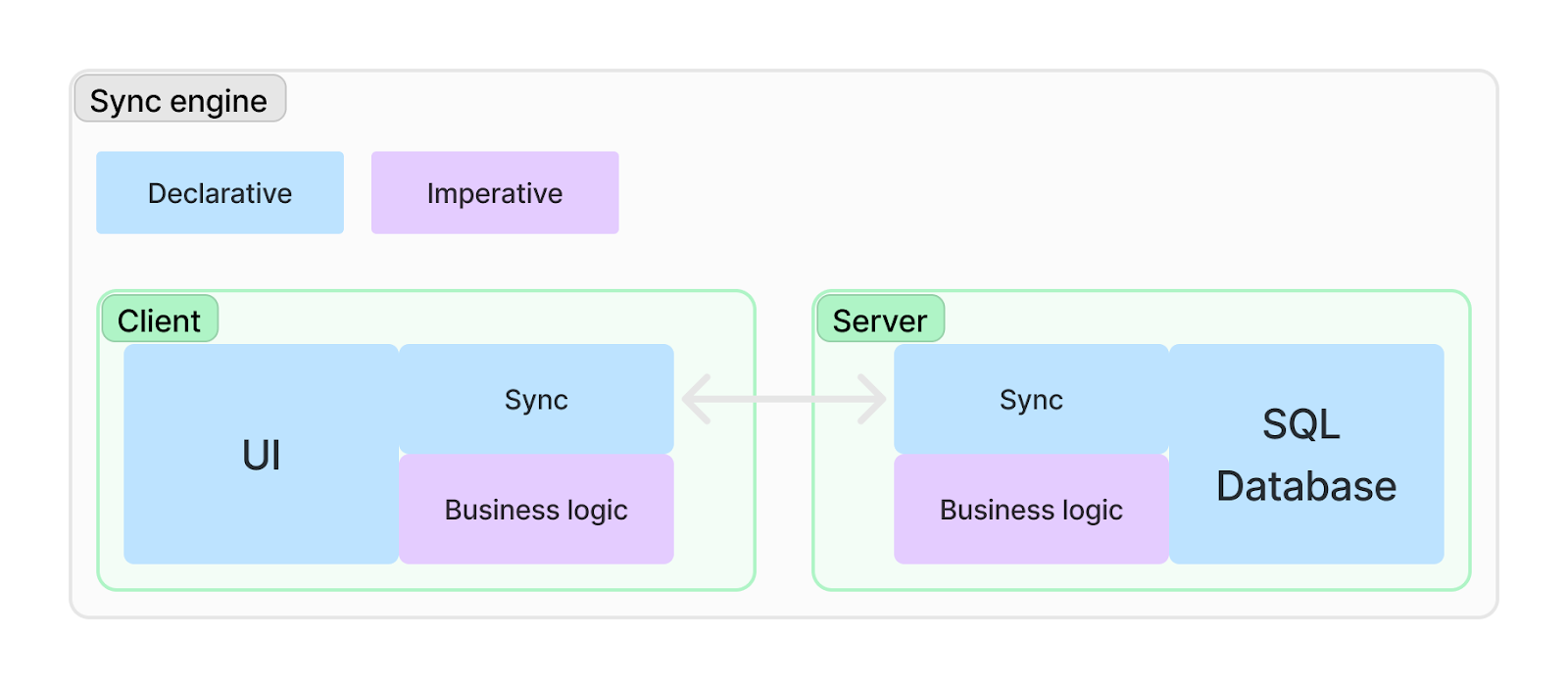
Moving to a declarative approach makes sense since most UIs today are built with declarative reactivity.
Securing the data
To make sure users can only access data they should have access to you have to add some configuration. Most sync engines require you to define a data schema and permissions. The permissions are usually based on a row-level security (RLS) pattern, similar to PostgreSQL's RLS, but simplified. The following is an example of how you secure the data using the InstantDB sync engine.
const rules = { |
That’s it. Now the sync engine is responsible for making sure that the permissions are enforced for all queries and updates.
Local-first
There is also a strong community around a related concept called local-first. You can find more info at Local-First Software, The past, present, and future of local-first - Martin Kleppmann (Local-First Conf), or the community localfirstweb.dev. A sync engine doesn’t have to include all local-first concepts but usually, there is a often a significant overlap. Generally, there is no full alignment around the terms local-first and sync engines. While local-first emphasizes independence from any service provider, sync engines usually require some sort of central data sync.
Interesting sync engines
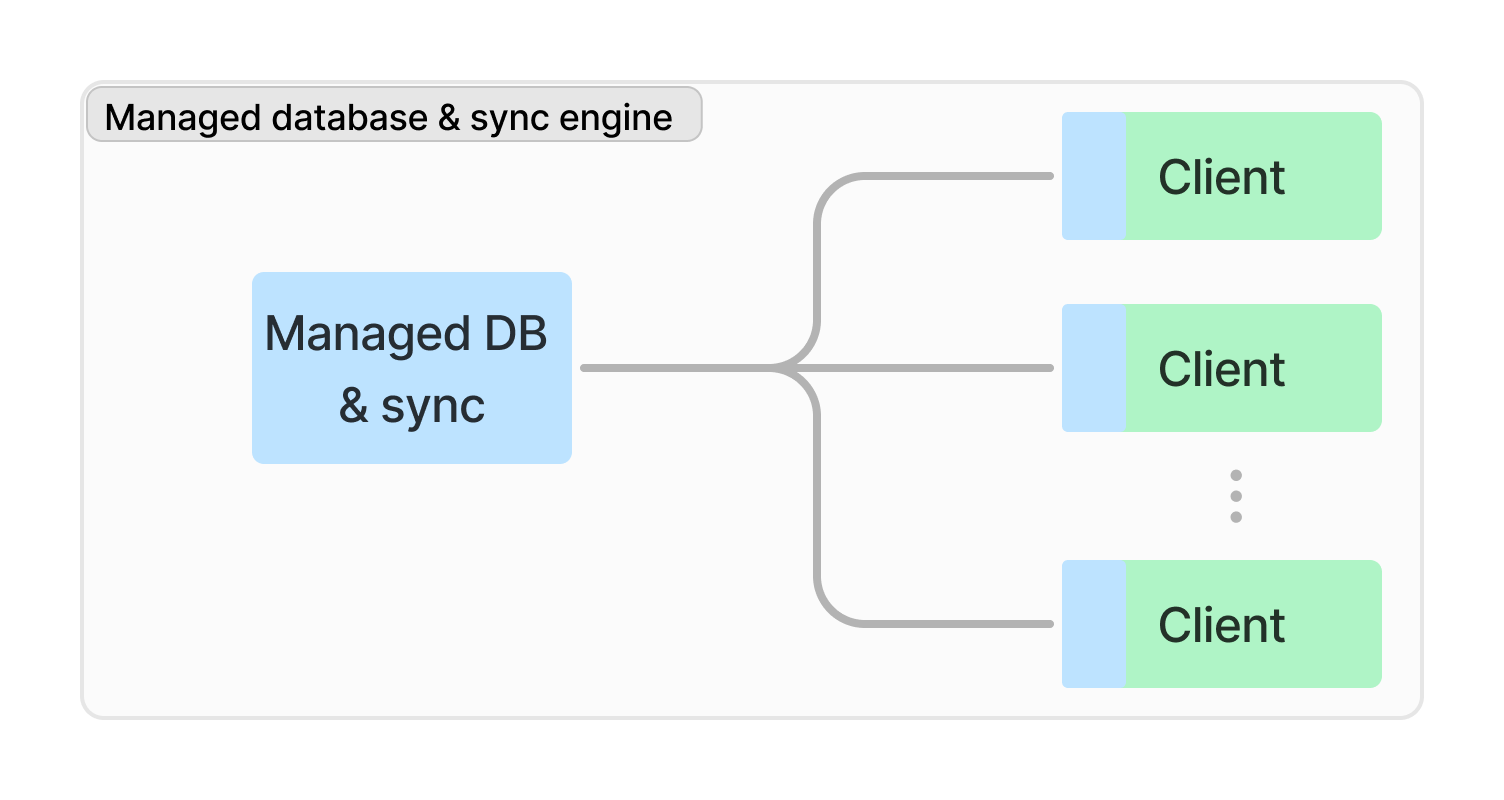
Some engines basically give you both a database and sync engine, like InstantDB, Triplit, and Supabase. Conceptually it looks like below.
Other engines are built so that you can plug it in between your existing database and the users of that database. For example Zero or Electric. With them, it conceptually looks like the following:

Did I miss something? Any feedback? Just reach out to me on X.
I’ve been playing around with InstantDBs sync engine while building rotatopotato.app, feel free to give it a try if you want!